

Compute Express Link (CXL) is an open interconnect standard that enables fast, coherent memory access between a host device, such as a CPU, and a hardware accelerator, which manages a heavy workload.
With the recent release of Compute Express Link 1.0, a consortium to enable this new standard was established, and its initial interface definition was made available.
Compute Express Link is anticipated to be used in heterogeneous computing systems with hardware accelerators that deal with artificial intelligence, machine learning, and other specialized activities.
Introduction to Compute Express Link Device Types:
This article focuses on the Compute Express Link device types. Compute Express Link uses three protocols: CXL.io, CXL.cache, and CXL.mem. The CXL.io protocol is used for initialization and link-up. Hence all CXL devices need to support it since the link cannot function without it.
Related Read: CXL 3.0 – Everything You Need To Know
The Compute Express Link OR CXL standard defines and may support three distinct Compute Express Link device types that come from various combinations of the other two protocols.
The three distinct Compute Express Link memory device types are together with the corresponding protocols, typical applications, and supported memory access types.
CXL Device Types
Only the data that the gadget needs can be cached. If the device caches the location, caches offer high-bandwidth and low-latency accesses.
Accessing a local memory location through a non-cached connection is substantially more effective than the 500-ns access latency and 50-GB/s bandwidth. This is helpful for Type-1 and Type-2 CXL protocol devices.

The Compute Express Link Consortium refers to the first as a Type 1 device, consisting of accelerators without host CPU memory. This type of device uses the CXL.io protocol, which is required, and CXL.cache to communicate with the host processor’s DDR memory capacity as if it were it’s own.
One possible example is a smart network interface card that can benefit from caching.
GPUs, ASICs, and FPGAs are Type 2 devices. Each requires the Rambus Compute Express Link.memory protocol and Compute Express Link .io and CXLcache protocol and has its DDR or High Bandwidth CXL Memory devices.
When all three protocols are active, the memory pooling of the host processor and the accelerator are both made locally accessible to the CPU. Additionally, they share a cache coherence domain, which significantly benefits heterogeneous workloads.
The final Type 3 devices use case made possible by the Compute Express Link.io and CXL.memory protocols is memory expansion.
When performing high-performance applications, a buffer connected to the CXL bus could be utilized to increase memory sharing bandwidth, add persistent memory, or expand DRAM capacity without taking up valuable DRAM slots.
Through CXL specification, high-speed, low-latency storage devices that would have previously replaced DRAM can now complement it, making add-in card, U.2, and EDSFF form factors available for non-volatile technologies.
Let’s examine the several CXL device types and the particular CXL interconnect verification issues, such as preserving cache coherency between a host CPU and an accelerator.
Type #1. CXL Device:
- Implements a fully coherent cache but no host-managed device memory
- Extends PCIe protocol capability (for example, Atomic operation)
- We May need to implement a custom ordering model
- Applicable transaction types: D2H coherent and H2D snoop transactions
Type #2. CXL Device:
- Implements an optional coherent cache and host-managed device memory
- Typical applications are devices that have high-bandwidth memories attached
- Applicable transaction types: All CXL.cache/mem transactions
Type #3. CXL Device:
- Only has CXL host-managed device memory.
- The typical application is a memory expander for the host
- Applicable transaction types: CXL.mem MemRd and MemWr transactions
The multiple hosts and device agent caches and the accompanying memories must remain coherent in a CXL.cache/mem design.
The host bias and the device bias are the two states for device-attached memory defined by the bias-based coherency model for a Type 1 CXL device. Each presents unique verification difficulties.
Compute Express Link spec attempts to provide reliable and effective access to memory dispersed across many components by acting as a high-performance I/O interconnect system.
Several of these components improve performance by using the local cache and minimizing memory access overhead, several of these components improve performance.
The Compute Express Link.cache protocol ensures that data stored across the components in either memory or local cache remains coherent and consistent with each component to accommodate this kind of arrangement.
A local cache is present because device components in Compute Express Link are frequently employed as accelerators for computationally demanding applications.
Therefore, the device attached memory can be forced to remove the line from its local cache and update the related memory address if the host component wishes to access the same memory area.
According to the Compute Express Link.cache protocol, communication between a device and a host consists of a series of requests, each of which is met with at least one response message and occasionally a data transfer.
Request, Response, and Data are the three channels that make up the interface. D2H (Device to Host) and H2D are the names of the channels according to their direction (Host to Device).
The Bias Based Coherency Model is used in a Compute Express Link-based system to enhance memory access performance. The device accesses the device-attached memory as if it were a conventional host-attached memory when it is in a host bias condition.
To access device-attached memory, a device must first send a request to the host, who will determine whether the requested line is coherent.
In contrast, the device is particular that the host does not have the line cached when the device-attached memory is in the device bias state.
In this situation, the host receives a uniform view of the device-attached shared memory regardless of the bias state. The device can access it without transmitting any transaction to the host.
Coherency is constantly maintained for device-attached memory in both the host and device bias states.
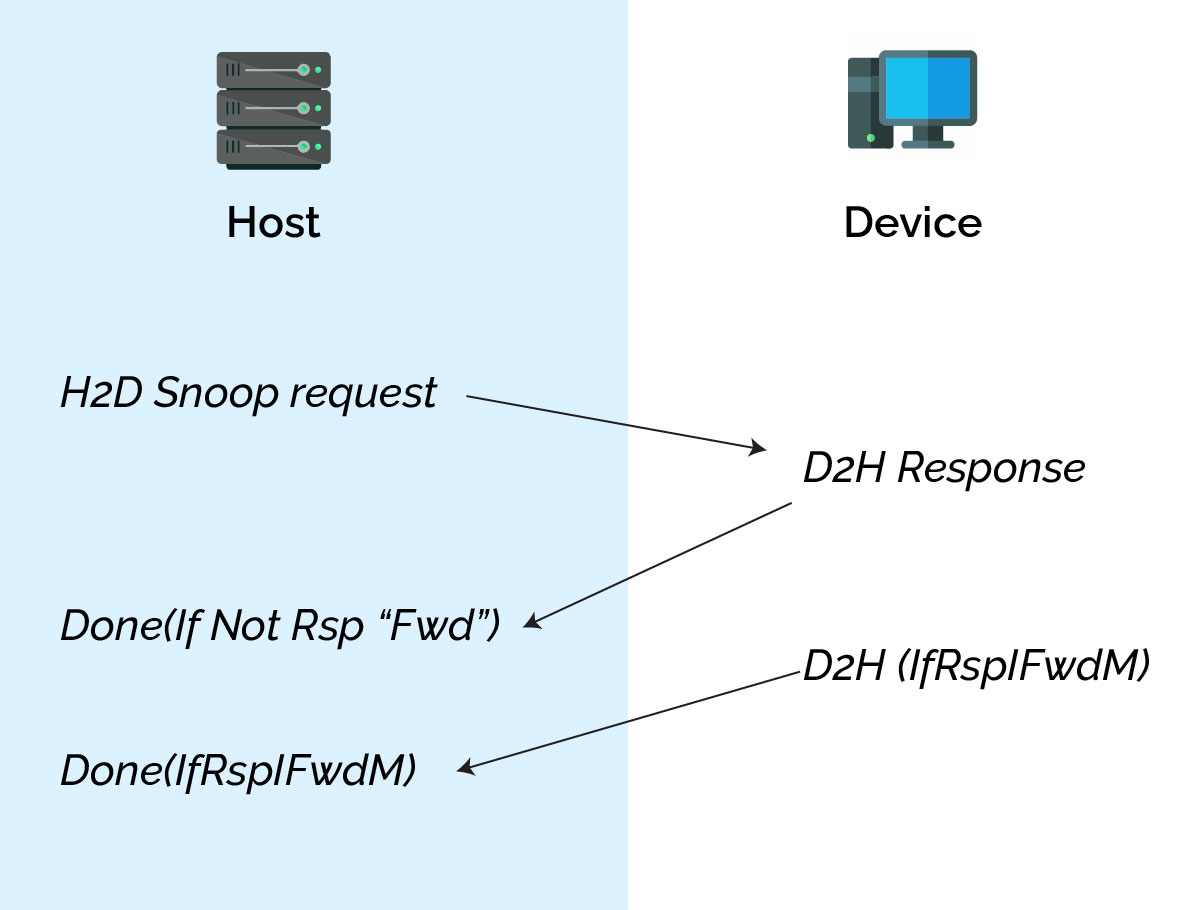
Compute Express Link.cache H2D Snp Transaction exchange:
- The host sends the H2D request SnpData to the device discovery
- The device receives the request and sends the D2H response as RSPI_FWDM to the host.
- The device sends D2H data to host
- After the host receives the response transaction is complete
Type 3 device primarily serves as a host memory expander. When responding to service requests from the host, the device uses Compute Express Link.mem. For Type 3 devices, there are two types of supported flows: Reading and writing are fluid.


Conclusion:
Compute Express Link 2.0 maintains full backward compatibility while supporting new applications including switching, resource pooling in a rack, persistence memory flows, and security upgrades in addition to the accelerator and memory expansion devices in a platform.







